publicclassWordcountMain{ publicstaticvoidmain(String[] args)throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "wordcount"); job.setJarByClass(WordcountMain.class); job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); boolean flag = job.waitForCompletion(true); if (!flag) { System.out.println("wordcount failed!"); } } }
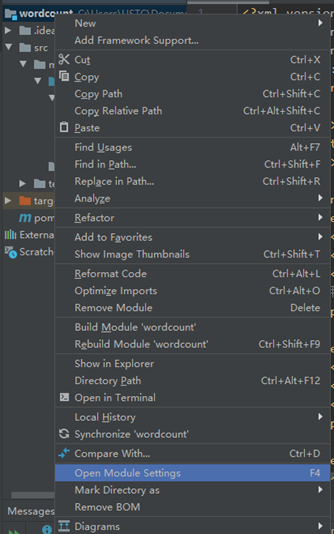
将项目打包成 jar
右键项目名称–Open Module Settings
Artifacts -> + -> JAR -> From modules with dependencies…
填写 Main Class(点击… 选择 WordcountMain),然后选择 extract to the target JAR,点击 OK。
勾选 include in project build ,其中 Output directory 为最后的输出目录,下面 output layout 是输出的各 jar 包,点击 ok
点击菜单 Build——>Build Aritifacts…
选择 Build,结果可到前面 4 的 output 目录查看或者项目结构中的 out 目录
执行验证
(这里采用 win 环境下的 hadoop2.7.6 作为例子,wsl 暂时未验证)
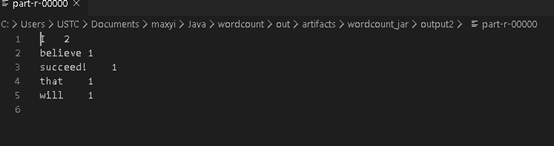
先在创建 jar 包路径下(C:\Users\USTC\Documents\maxyi\Java\wordcount\out\artifacts\wordcount_jar)建立一个 input1.txt 文档,并添加内容 “I believe that I will succeed!” 并保存。等会儿要将该 txt 文件上传到 hadoop。
运行 hadoop 打开所有节点 cd hadoop-2.7.6/sbin start-all.cmd
运行成功后,来到之前创建的 jar 包路径,将编写好的 txt 文件上传到 hadoop cd / cd C:\Users\USTC\Documents\maxyi\Java\wordcount\out\artifacts \wordcount_jar hadoop fs -put ./input1.txt /input1 可以用以下代码查看是否上传成功。 hadoop fs -ls /